Efficient Data Warehousing with MotherDuck, DuckDB & dbt#
In this tutorial, we will explore how to build an efficient data warehousing solution using MotherDuck, DuckDB, and dbt. These tools together provide a powerful and flexible environment for managing and analyzing large datasets. You will learn how to set up your data warehouse, integrate it with dbt for data transformations, and leverage DuckDB for fast, in-memory analytics.
Tutorial overview#
This tutorial will explore a pattern for using dbt for data loading in addition to transformation. A high level overview of the pattern can be seen below:
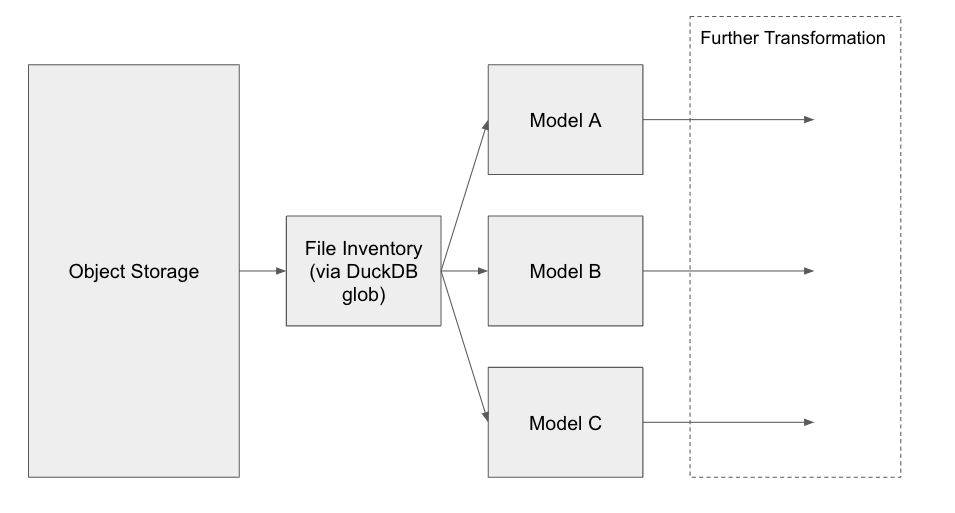
In addition, it will use plotly dash to serve some analytics directly from MotherDuck in the browser.
What is dbt?#
dbt (data build tool) is an open-source command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively. Developed by dbt labs, dbt allows users to write modular SQL queries, test data quality, and document data transformations. By using dbt, teams can version control their SQL scripts, automate data transformations, and ensure consistency and reliability in their data pipelines.
What is DuckDB?#
DuckDB is an in-process SQL OLAP (Online Analytical Processing) database management system designed for fast analytical query workloads. Unlike traditional databases that run as a separate server process, DuckDB is embedded directly into your application, providing high performance and low latency for analytical queries. It supports complex SQL queries, including joins and aggregations, and is optimized for handling large datasets efficiently. DuckDB is particularly well-suited for data science and analytical tasks, offering seamless integration with tools like Python and R, and enabling in-memory analytics without the need for a separate database server.