4. Handling race conditions#
The models as built thus far can run into race conditions where files are added or removed from the s3 bucket during exection. We can reduce the likelihood of this type of failure by materializing our list of files. While this does not prevent deletion of files from impacting our dbt build process, it importantly will make sure that no new files are injected while dbt is running.
The data flow will look like this:
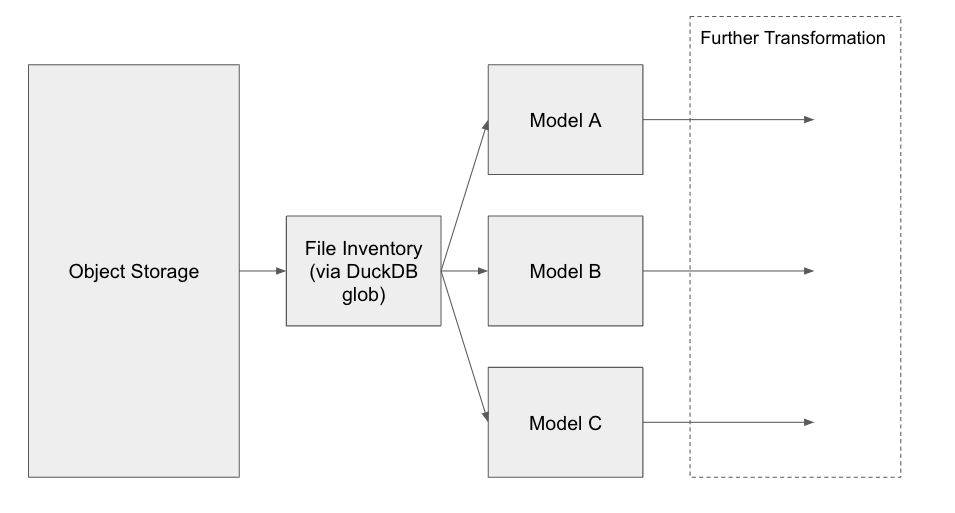
Because we are materializing a list of files, we can be a bit more sophisticated with how we pass this file inventory into our dbt models, for example, we can now categorize our files and persist some meta-data, like modified timestamps. While typically files in object storage are treated as write once, if the file timestamp updates, we may also want to handle that as an incremental update.
DuckDB contains a function called read_blob(), which returns meta-data about each file. This meta-data can be helpful for identifying which file to treat as the current valid version, especially when file names are inconsistent or generic.
You can use this function similar to read_csv(), by passing a path to an S3 bucket.
select *
from read_blob('s3://us-prd-motherduck-open-datasets/stocks/**/*');
Exercise 4.1
Build a dbt model that gets all files from an s3 path, categorizes each file to a specific tabular entity, and persists the timestamp.
Referencing our files model from our other models#
Now that we have a list of files with some meta-data, we can re-implement our models that are load data from S3 to be fully incremental. In order to do this, we want to:
Create a list of all files that match certain meta-data filters in a
pre_hook.Pass that list to a
read_csv()function so that DuckDB knows which files to process.Make sure the
is_incrementalbits and theunique_keymatch your desired behavior.
Pre-hooks in two sentences#
In order to get the SQL variable my_list in the context for the subsequent query, we have to also invoke it with a pre_hook. A pre_hook is simply a SQL statement that is executed before the model runs, while a post_hook runs immediately after.
Exercise 4.2
Create and run a dbt model with a pre_hook that populates a list, then return that list in the body of the model.